
Im Zusammenhang mit IIoT oder Datenanalyse tauchen immer wieder die Begriffe Cloud und Edge Computing auf. Während der Begriff Cloud den meisten spätestens durch diverse Dienste von Google oder Amazon vertraut ist, ist Edge Computing ein eher unbekanntes Feld. Dennoch ist teilweise zu hören, dass Edge Computing das neue Cloud Computing wird. Stimmt das? Aber schauen wir uns beides erst einmal kurz an.
Cloud Computing und Edge Computing in Kürze
Die Cloud ist eine IT-Infrastruktur, die nicht lokal installiert werden muss, sondern z.B. über das Internet zur Verfügung steht. Der Cloudanbieter bietet verschiedene Dienste wie beispielsweise Speicherplatz oder Anwendungssoftware zur Miete an. Der Vorteil liegt auf der Hand: Der Endnutzer muss sich keine Gedanken mehr über ausreichenden Speicherplatz, Lizenzkosten oder Rechensysteme machen, bei denen er sich zusätzlich um die Wartung kümmern müsste, was unter Umständen extrem kostenintensiv sein kann.
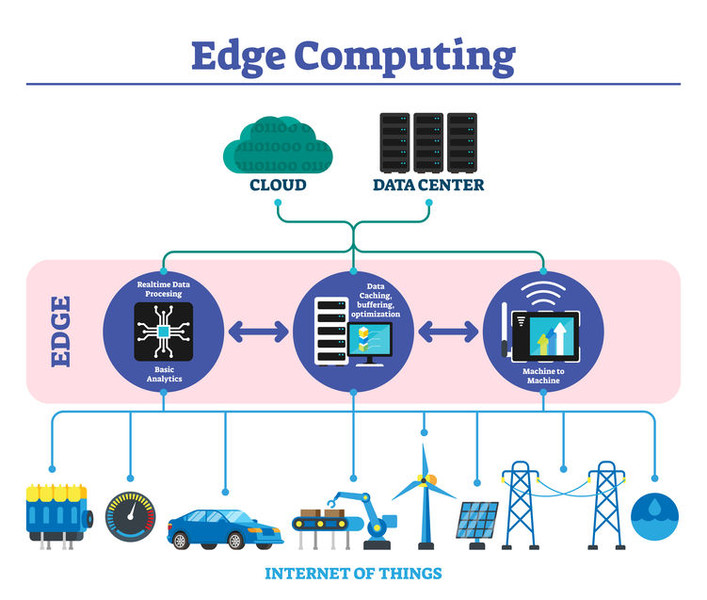
Beim Edge Computing werden Daten direkt am Entstehungsort verarbeitet, also dezentral am Rande des Netzwerks – daher der Begriff „Edge“. Was das im Vergleich zur Cloud bedeutet, schauen wir uns am besten mal an einem Beispiel an.
Beispiel Kavitationserkennung
Nehmen wir die Kavitationserkennung von Yokogawa. Kavitation kann durch Implosion von sich unter bestimmten Bedingungen in Flüssigkeiten bildenden Dampfblasen zu starken Schäden an Pumpen und Ventilen führen. Um dieses zu verhindern, ist eine möglichst frühzeitige Erkennung der Blasenbildung notwendig. Die Lösung von Yokogawa setzt auf die Auswertung feinster Änderungen in den Druckschwankungen, hervorgerufen durch die Implosion der Blasen. Damit diese Druckschwankungen aber überhaupt sichtbar und damit auswertbar sind, müssen die Messwerte mit einer sehr hohen Auflösung aufgenommen werden. In diesem Falle alle 100 ms. Außerdem müssen mehrere interne Parameter des eingesetzten Differenzdruckmessers ausgewertet werden. Da kommt schon ein bisschen was zusammen.
Schnell “at the Edge”
Wollte man die notwendigen Berechnungen in der Cloud durchführen, würde das einen nicht unerheblichen Datentransfer bedeuten. Und dazu einen ziemlich unnötigen. Denn letztendlich interessiert nur das Ergebnis – ein Maß für die Höhe der Druckschwankungen sowie eine Alarmierung bei kritischen Werten. Daher macht es in so einem Fall wesentlich mehr Sinn, die Daten direkt vor Ort auszuwerten. Im genannten Beispiel ist der Differenzdruckmesser mit einem Controller verbunden, der die Höhe der Druckschwankungen berechnet. Ausgehend vom Level der Druckschwankungen im Normalzustand ermittelt er zusätzlich Schwellwerte für kritische Level beginnender und starker Kavitation. Überschreiten die Druckschwankungen die Schwellwerte, kann so ohne Verzögerung reagiert werden, beispielsweise durch eine direkte Abschaltung kritischen Equipments. Also ohne Latenzzeiten bei der Datenübertragung, wie sie beim Cloud Computing auftreten. Edge Computing ist in diesem Fall also sicherlich die geeignetere Herangehensweise.
Übersicht in der Cloud
Geht es um Maintenance-Aufgaben und eine gute Übersicht über den Zustand des Maschinenparks, macht es natürlich Sinn, zu wissen, wo Kavitation auftritt. Aber auch, wo Equipment an der Verschleißgrenze ist oder sich ein Defekt anbahnt. In diesem Fall benötigt ein Maintenance Engineer die Daten verschiedenster Anlagenteile sowie diverse Kenngrößen, um gezielt planen zu können, in welchem Bereich Handlungsbedarf besteht. Auch hier können ihm Algorithmen helfen, beispielsweise solche, die datenbasiert die Lebensdauer von Equipment bestimmen, Stichwort Predictive Maintenance. Das sind jedoch nicht unbedingt zeitkritischen Betrachtungen, die eine schnellstmögliche Reaktion verlangen. Aber das Zusammenführen und die gemeinsame Verarbeitung von Daten aus verschiedenen Quellen. Und hier hat Cloud Computing ganz klar die Nase vorn.
Also Edge Computing doch nicht das neue Cloud Computing?
Im Gegensatz zu Edge Computing eignet sich Cloud Computing folglich eher für nicht zeitkritische Aktionen und Auswertungen, um einen umfassenderen Blick über mehrere Datenquellen zu erhalten. Es kann die Echtzeitservices vom Edge Computing nicht leisten, da vom Device in die Cloud Latenzzeiten entstehen. Edge Computing besticht hingegen durch seine Geschwindigkeit und Lage nahe am einzelnen Device. Dessen Einsatz ist dann angebracht, wenn es um zeitkritische Operationen geht, d.h. wo in Echtzeit Entscheidungen notwendig sind, wie beispielsweise beim Erkennen von Anomalien. Aber auch da, wo keine Konnektivität zum Rechennetz zur Verfügung steht oder keine vollständige Übertragung der Daten an eine Cloud notwendig bzw. gewollt ist.
Cloud und Edge Computing sind also zwei verschiedene Anwendungsbereiche, die nebeneinander – aber auch miteinander – existieren und beide ihre Daseinsberechtigung haben. Das eine wird das andere daher nicht ablösen oder ersetzen. Allerdings sind beim Edge Computing in der näheren Zukunft die größeren Entwicklungen zu erwarten, da es noch nicht so stark ausgebaut ist wie das Cloud Computing. In Sachen Hype mag es also durchaus sein, dass Edge Computing das neue Cloud Computing wird.
Bildrechte Titelbild: EVERST-stock.adobe.com


