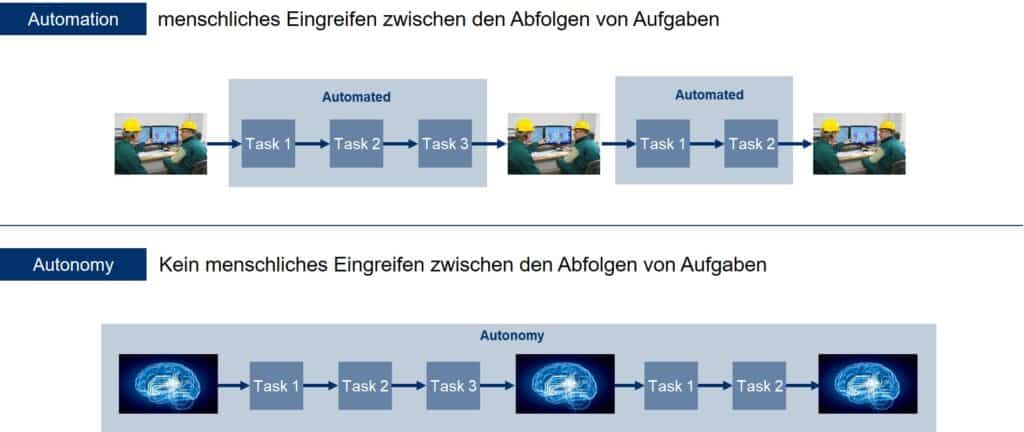
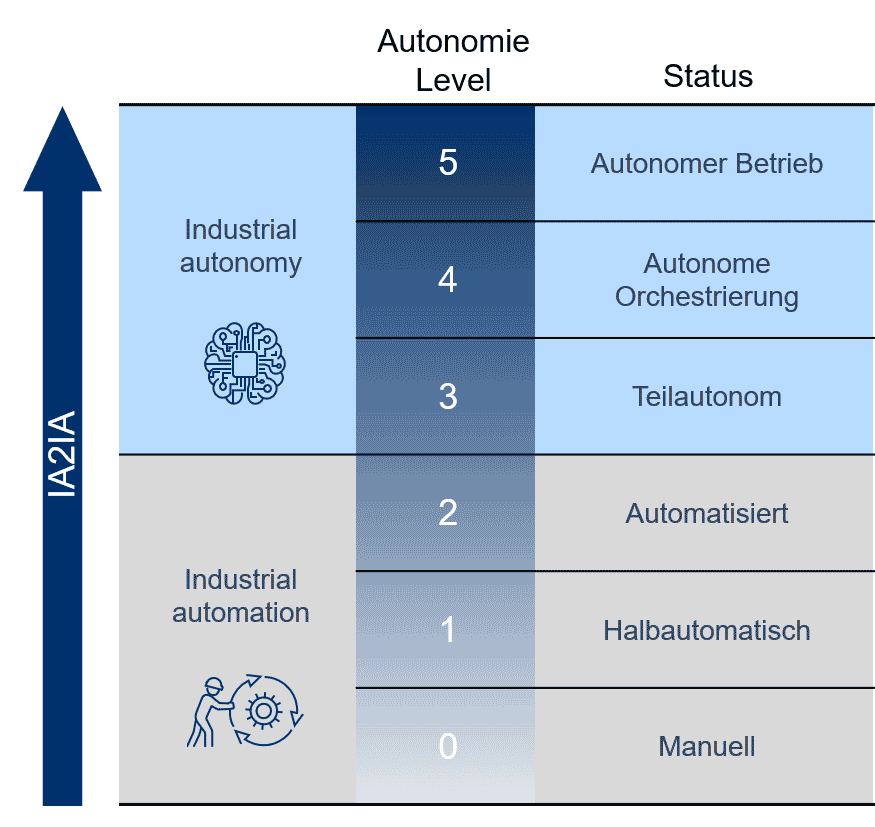
De weg naar industriële autonomie zal een stapsgewijs traject zijn, en dat moet ook. Toenemende autonomie betekent tegelijkertijd een afname van de menselijke tussenkomst. In het verleden werden beslissingen vaak genomen op basis van ervaring, maar nu verschuift de focus naar een andere basis voor besluitvorming: data. Het gebruik ervan is vooralsnog niks nieuws. De vereisten aan de kwaliteit van data zijn echter heel anders wanneer deze gegevens voor een autonome exploitatie gebruikt moeten worden.
Data stapelen zich in steeds grotere hoeveelheden op. Door digitalisering en de IIoT zullen deze hoeveelheden blijven toenemen. Ook het belang van data voor de bedrijfsprocessen van ondernemingen wordt steeds groter. Vroeger werden data voor specifieke toepassingen in afzonderlijke databanken opgeslagen. In de toekomst is dit niet meer mogelijk zonder netwerkvorming en gezamenlijke evaluatie. Big Data-analyses bieden legio mogelijkheden om verschillende soorten data met elkaar in verband te brengen, om zo nieuwe bedrijfsmodellen te genereren of processen doeltreffender en dientengevolge autonomer te maken.

Kostenfactor van een gebrekkige datakwaliteit
De datakwaliteit heeft niet alleen betrekking op de dataverzameling zelf, maar ook op het gebruik ervan binnen alle bedrijfseenheden van een onderneming, alsmede op de afstemming van die data op verschillende gebruikssituaties en de presentatie ervan. Uiteraard moet dit alles gebeuren met inachtneming van de databeveiliging en alle wettelijke voorschriften. Gezien deze complexiteit is het niet verwonderlijk dat veel op data gebaseerde projecten nog steeds zeer hoge kosten met zich meebrengen of zelfs mislukken.
De kosten ontstaan al meteen aan het begin, door de grote inspanning die nodig is om de noodzakelijke data te verzamelen en om deze in de voor de evaluatie vereiste vorm en kwaliteit om te zetten. Als de onderliggende data geheel onjuist zijn of als er relevante informatie ontbreekt, dan bestaat er een groot risico op onjuiste beoordelingen. Tijdens de rest van het traject ontstaan extra kosten door de online implementatie van op data gebaseerde toepassingen in ongeschikte infrastructuren. Om nog maar te zwijgen over het onderhoud van dergelijke systemen. De inspanning kan voor afzonderlijke projecten te rechtvaardigen zijn in vergelijking met de omschakeling van een volledig databeheersysteem. Het is echter niet mogelijk om hiermee een verregaande autonomie van systemen te bereiken.
Beschikbaarstelling van de noodzakelijke infrastructuur
De 3B Maturity Benchmark van de Singapore Economic Development Board is gebaseerd op de Smart Industry Readiness Index (SIRI) en illustreert op levendige wijze het belang van de beschikbaarheid van data voor bedrijven. Een SIRI-beoordeling belicht de centrale gebieden van een bedrijf met betrekking tot hun volwassenheidsniveau op het gebied van Industrie 4.0. Hoewel de verschillen tussen de drie groepen (1. Bottom Performers, 2. Broad Middle en 3. Best-In-Class) op alle gebieden relatief constant zijn, springt de categorie dataconnectiviteit er duidelijk uit.
De toonaangevende bedrijven liggen ver voor op de andere vergelijkingsgroepen wat betreft de productie van netwerken. Alle componenten en computersystemen zijn uitwisselbaar en veilig met elkaar verbonden. Communicatie vindt hoofdzakelijk real time plaats.
Voorafgaand aan andere activiteiten, zoals de verticale en horizontale integratie of de invoering van intelligente systemen, hebben de ondernemingen voorrang gegeven aan investeringen in de noodzakelijke infrastructuur. Een veilige en snelle onderlinge uitwisselbaarheid op alle niveaus is immers een basisvoorwaarde voor autonome systemen, net als datakwaliteit.
Is een hoge datakwaliteit een kostenfactor?
De inspanning en ook de kosten schrikken echter vaak af. Is het waarborgen van een hoge datakwaliteit dan ook een kostenfactor? Laten we het eens vanuit de andere kant bekijken. Intelligente, op data gebaseerde systemen zijn in de eerste plaats bedoeld om besparingen te realiseren. Deze besparingen houden dus rechtstreeks verband met de gebruikte data. In een simpele formule betekent dit het volgende: hoe groter de besparingen, des te groter de waarde van de data. Plus: hoe beter de datakwaliteit, des te beter de toepassing en dus waarschijnlijk ook de besparingen. Op die manier kunnen de kosten voor het verstrekken van de data worden afgewogen tegen de inkomsten uit het gebruik ervan. Een hoge datakwaliteit is dus geen kostenfactor. Deze vertegenwoordigt veeleer een waarde die de kosten van de beschikbaarstelling ervan moet compenseren. Het is dus de moeite waard om te investeren in een goede datakwaliteit. Op de weg naar industriële autonomie zijn kwalitatief hoogwaardige data onontbeerlijk.
Beveiligen en onderhouden
Een dergelijke implementatie moet altijd gepaard gaan met deugdelijke Data Governance. Alleen door te zorgen voor een alomvattend raamwerk is het mogelijk een goede datakwaliteit te handhaven, naast het onderhoud, de bescherming, de beveiliging en de naleving van de voorschriften. Bedrijfsbrede richtlijnen en een centraal georganiseerd databeheer met uniforme processen en methoden helpen de data infrastructuur te systematiseren. Aan de hand hiervan wordt een continu proces op gang gebracht, waardoor ook de kosten op voorhand geraamd kunnen worden om deze in evenwicht te kunnen brengen.
Smart Manufacturing: grenzen vervagen – de vereisten blijven